Information Processing Cycle: 4 Main Components With Example
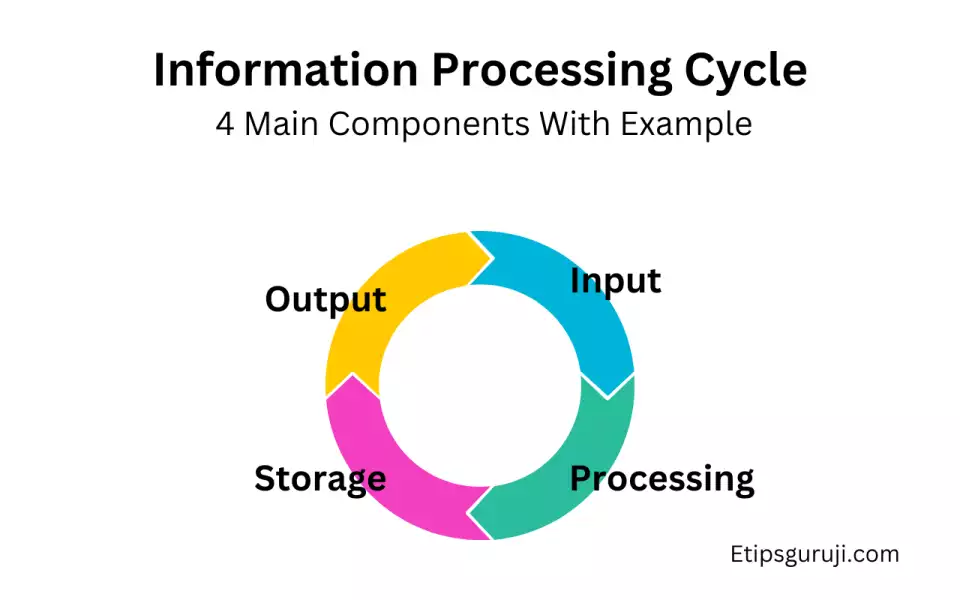
In computer science, the Information Processing Cycle describes the four critical stages—Input, Processing, Output, and Storage—that a computer uses to operate.
These stages define the fundamentals of data processing and understanding them is crucial to grasp how computers and software applications function.
This article breaks down these stages and examines their connections, applications, associated challenges, and their influence on contemporary technology.
4 Main Components of the Information Processing Cycle
1. Input
The first phase of the Information Processing Cycle is Input. It refers to the raw data entered into a computer system.
This could be through various means such as a keyboard, mouse, scanner, or even voice commands.
The importance of quality and accuracy of input data cannot be overstated. Errors in input often result in incorrect output.
Practical Examples of Input:
- Keyboarding: Whenever you type on a computer, you’re providing input.
- Voice command: Speaking to voice-activated systems, like Cortana or Siri, is another form of input.
2. Processing
Once data is input into the system, the next phase is Processing. Here, the central processing unit (CPU) comes into play.
It carries out the instructions of a computer program to manipulate the data. The role of the Operating System is also vital, as it manages the system’s resources during this stage.
Practical Examples of Processing:
- Executing a Program: Running software on your PC involves data processing.
- Calculating Spreadsheet Formulae: When you use Excel to perform calculations, you’re experiencing the processing phase in action.
3. Output
Next, we have the Output phase. This is where the processed data is presented to the user.
It could be in the form of visual display on the screen, printed documents, audio, or even tactile feedback.
Practical Examples of Output:
- Screen Display of Results: When you see the results of a Google search, it’s an instance of output.
- Printout of Reports: When a spreadsheet calculation is printed, it’s output is in a physical form.
4. Storage
Lastly, there’s the Storage phase. This is where data, whether input or output, gets stored for future use.
Storage mediums range from RAM (temporary, quick access) to Hard Drives, SSDs (long-term, slower access), and Cloud Storage (off-site, internet access).
Practical Examples of Storage:
- Saving a Document: When you press “Ctrl+S” to save your work in Microsoft Word, you’re utilizing storage.
- Uploading a File to the Cloud: Saving your pictures on Google Drive is another example of the storage phase.
The Interconnectivity of Information Processing Cycle Components
How Components Work Together
The components of the Information Processing Cycle don’t work in isolation. They have a sequential interaction, meaning one phase leads to the next, creating a cycle.
- Input is taken from the user.
- This input is processed based on the computer’s instructions.
- The processed data forms the output.
- This output can then be stored for future use.
Feedback plays an integral role in this cycle. For example, the output of one operation can serve as the input for the next operation.
How Information Processing Cycle is used in Web Browsing?
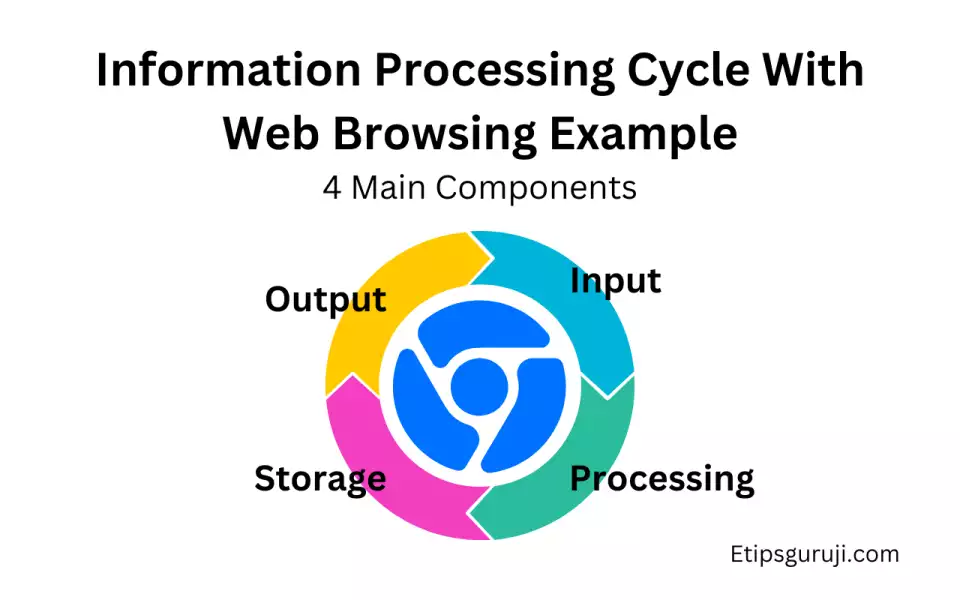
1. Input
In web browsing, the input is typically provided by you typing a URL or search term into the browser or clicking a link.
2. Processing
The browser fetches the requested page from the web server, which is a form of processing. Then, it also processes the HTML, CSS, and JavaScript to render the page.
3. Output
The output is the display of the web page on your screen. Any videos or sounds that play as part of the page are also considered output.
4. Storage
Web pages are often cached (stored) to make future access quicker. The browser also stores cookies and other session data.
Advanced Concepts in the Information Processing Cycle
A. Parallel Processing
In Parallel Processing, multiple processors perform tasks simultaneously, enhancing the speed of data processing.
Practical Examples of Parallel Processing:
- Multithreaded Applications: Software that can do multiple tasks at once.
- GPU Processing: Graphics cards are excellent at doing many tasks in parallel.
B. Real-time Processing
Real-time Processing means the system is able to respond instantly to input. This is crucial in systems requiring immediate feedback.
Practical Examples of Real-Time Processing:
- Video Game Rendering: Games need to respond instantly to player actions.
- Autonomous Driving Systems: Self-driving cars need to make split-second decisions.
C. Distributed Processing
Distributed Processing is where processing is spread across multiple computers, often across a network.
Practical Examples of Distributed Processing:
- Cloud Computing: Many cloud services use distributed processing to handle large tasks.
- Blockchain Technologies: Cryptocurrencies like Bitcoin rely on distributed processing.
Challenges and Solutions in the Information Processing Cycle
1. Data Quality and Validation
Poor data quality can cause issues in the processing cycle. This can be mitigated by using validation techniques to ensure data is accurate and complete.
2. Efficiency and Performance
Efficiency is a big challenge in maintaining a smooth data processing cycle. It can be enhanced by optimizing software, upgrading hardware, or using more efficient data structures.
3. Data Security and Privacy
Securing the data throughout its lifecycle is crucial. Encryption, firewalls, and secure coding practices are all part of this solution.
Impact of Information Processing Cycle on Modern Technologies
1. Role in Artificial Intelligence and Machine Learning
In AI and ML, the information processing cycle involves training models on large datasets (input), processing them using various algorithms, producing results (output), and refining the models based on these results (storage and feedback).
2. Role in Big Data and Analytics
Information processing in big data involves gathering vast amounts of data (input), processing this data to find patterns or trends, presenting these findings (output), and storing the results for future analysis.
Read More: